The TTL Trick
Or the importance of knowing networking fundamentals so you can blame the network 🙂
https://medium.com/@pjperez/the-ttl-trick-c78f1279817d#.auia1ug8s
I have met several network engineers during my life. Most of them are very clever and pragmatic people.
These engineers can solve the majority of the problems in their network by looking at logs and configuration files, so they slowly move away from the very foundation of their networks: The protocols.
I’m not going to claim I’m a rockstar IP or TCP guy, but I can say that I reallylike to know what’s under the hood and love to see all the pieces of the puzzle coming together to paint the final picture. This has helped me multiple times in the past. One of these little pieces of knowledge, which has become a trick after the years, is what I like to call The TTL Trick.
Help! $YOURAPP doesn’t work!
Helping people running their distributed applications has probably been the most common task through my career.
My troubleshooting methods have changed over the years, especially when I moved from actually managing the network (where I would check logs and apply my logic) to working for a software company, where my company’s applications could be affected by a potential network issue and I had zero access to the network gear.
Right now, what I always ask for is for simultaneous network captures. Simultaneous as in client and server captured at the same time. Eventually this could be extended to more captures from other devices in between, but in the first place it’s not always easy to get the needed information to even draw a little network diagram, less to understand where should we capturing.
So, in summary, pcaps or it didn’t happen. By the way, I like my captures full, not filtered based on someone else’s criteria, thank you. It makes me sad to not find the root cause of an issue because someone decided to only capture the application’s traffic, not capturing that ICMP “fragmentation needed but DF bit set” that tells you there’s some MTU issue.
Why do I really, totally, completely need these captures? For lots of reasons, but the focus of this article is on the TTL header, so that’s why.
The TTL or Time To Live is a field in the IP header:
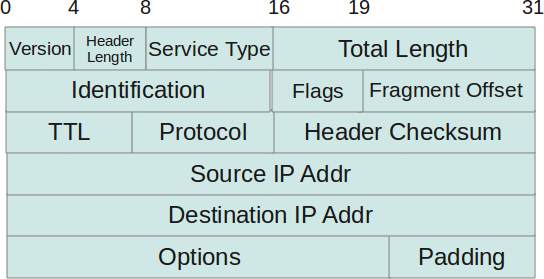
This field could be considered a security feature, thought to avoid packets moving through your network in a routing (or layer 3 — remember OSI) loop until the end of the days. A routing loop happens when a packet that needs to get from A to B is bounced as a ping-pong ball between two hosts that have conflicting routes.
How does such a tiny field in the headers avoid packets looping ad infinituminside your network? In a classy way.
Every time a new packet is put on the wire, it has an initial value in the TTL field that gets decreased when the packet is routed to another network. Once the value in the TTL header reaches zero, the packet is dropped and not forwarded nor accepted by the device that just received it.
I told you it was classy.
Now you will be wondering what’s the initial TTL value? — It depends, and it actually depends on the vendor of the OS (actually depends on the network stack, but these two are usually in a one to one relationship). Here are some values I remember on top of my head:
- Windows OS: 128
- Most Linux distros: 64
- Some Cisco gear (e.g. ASA): 256
- F5 LTM, even though it’s Linux based, seems to use 256 too.
- Riverbed seems to use 64 on their WAN accelerators.
- Watchguard and Fortigate firewalls seem to use 64 as well.
In all honesty, the different maximum values never were a big problem for anyone nor reason for a big discussion.
A routing loop is a problem big enough for a network engineer, who at that stage probably doesn’t care if the lost packets jumped 64 or 256 times. I guess engineers working on very high bandwidth environments with routing nightmares (ISPs? Telcos? Big Corporate?) might not agree with my statement, but still not the point of this article.
What’s the TTL trick then? Scenario 1
Now let’s imagine for a second that you have your fancy application running on your fancy network, but some connections are lost. The described symptoms are that a user is working and suddenly there’s an error on screen about a lost connection. Of course you will pass the ticket to the network guys. I mean, the error says connection right? There might be even an IP address somewhere. All good…
All good until the network team comes back and shows you a packet capture from the client side, where your server is sending a TCP Reset to kill the connection. Dammit!
Now you have two tasks: Send the ticket to the server guys (it has to be their fault now) and check the application logs for the first time, just in case there’s something quite not right there. Now here comes a first surprise: You have a server-side error message that claims the client actually killed the connection. You know what? It has to be the network but you can’t prove it.
Or can’t you? Of course you can! remember that fancy packet capture the network team sent across to show you how it was totally not their fault? Well, you better install Wireshark now and open the capture to analyse.
As it turns out, both your client and the server are running Windows, and now thanks to this article you know the Windows TTL is 128.
You brush up your Wireshark skills and find the broken conversation (i.e. you apply the filter the network team told you). There it is, A fancy three-way handshake. You remember that from your CCNA (syn, syn ack, ack).
Care to look at any packet coming from the server for me please? You check the TTL field in the IP headers and write down the number on your notepad. It’s probably something close to 128. Let’s say you see 124, so there are 4 routing hops between your user and your server.
Now you’re going to scroll down (unless you’re a monster that reverse orders the packet list!) and find the TCP Reset packet. Click. Click click. Expand IP headers. Boom!

“Fuck you” said the network
The TTL is 255 and the header checksum is correct, so that value is real. What the actual f…?
Some network device, one hop away (so not in your user’s subnet gateway), is royally screwing you. This device crafted the TCP Reset packet from scratch, for some weird (security?) reason.
With this little information you have been able not only to blame those pesky network engineers, but also showed them where in the network is the problem.
If I was you, I would call it a day and go home because it can’t get any better from here. Remember to get your pay raise on your way out.
What’s the TTL trick then? Scenario 2
Now here comes the other common scenario, which is also a bit more tricky.
On the previous scenario we could have blamed a network device with a simultaneous capture and showing: That both sides received a TCP Reset from the remote side, but they didn’t send any.
On this second scenario, there are no new packets in the network.
Your user complains about the same symptoms and a simultaneous trace actually shows that your server is sending a TCP Reset to the client. OK, it must be the server guys fault, let’s blame them! but let’s also check our application logs just in case. After some troubleshooting time, you find that the server actually receives corrupt data from the client, so of course it doesn’t like that data, throws an exception and resets the connection. Talk about resilient software.
Time to trace on the client, maybe?
Tracing on the client shows that the data is right. Oh well, what could be happening here? Now you’ve already spent a few precious hours, plus involved the server and network guys who said they couldn’t see any problems either.
Too many man-hours for a problem that you could have already solved.
Back to those simultaneous traces. Server-side shows the user’s packets have a TTL of 58, while the user-side trace shows the packets have a TTL of 128.
Well, I’m a firm believer of The Church of the Asymmetric Routing (TCAR), but there’s no way on Earth there are 70 hops difference between the two paths.
You know again that both the client and server are running Windows, so their TTL must be close to 128 in your company’s internal networks. Why do these packets have their TTL changed? Looking again at the user-side trace, you can see they leave the user’s workstation with a TTL of 128. Yep, the TTL has been changed somewhere. Somehow.
Let’s go back once again to the server-side trace. Look at the three way handshake. Chances are the syn and ack packets from the user side will not have a TTL of 58, but something around 122 (depending on the asymmetry of your network). Why do these packets have TTL 122 and the rest TTL 58?
Application Layer Filtering, Intrusion Protection / Detection, Deep Packet Inspection, you name it. All these technologies care about layer 7 protocols, so they’ll try to inspect the TCP (or UDP) payload to look for those layer 7 protocols (and their payloads!) like e.g. HTTP or even your application’s 😉
While the connection is being established, these network appliances will act as a normal firewall: matching rules, forwarding packets, creating a connection entry in the table. Your packets during the three way handshake are mostly uninteresting and are forwarded unharmed, but as soon as the L7 protocol that your application uses comes into play, these appliances will rip the packets apart and try some magic on them like sanitization, compression, optimization, etc
Chances are the data will not follow your application’s protocol any more and your server will not understand the packet, thus throwing an exception and killing the connection. You know, you could’ve handled that exception. I mean, it’s not like transport protocols like TCP don’t have mechanisms to retransmit packets, right?
In any case, this has happened and still happens more often than some networking (and especially network security) vendors would like to admit. It is fucking difficult to get application filtering right.
Show the network team this capture, tell them that they left running some obscure magical feature on a firewall in the network (potentially running an OS based on Linux, due to a TTL close to 64) and that it’s screwing up your application. In the meanwhile, file a bug to make the application more resilient to these quirks.
Another.Case.Solved.